Consistência Eventual
Em sistemas síncronos tradicionais (banco de dados único), quando você escreve um dado, na próxima leitura ele já está lá. Isso é consistência forte.
Em sistemas distribuídos com Kafka, o serviço A publica um evento e o serviço B vai processar em algum momento. Pode ser em 10ms, pode ser em 5 minutos se estiver com fila acumulada.
Consistência eventual significa: se você parar de escrever, eventualmente todos os nós convergem para o mesmo estado.
T=0s: Pedido criado no Serviço A. Estoque ainda não atualizado.
T=1s: Evento publicado no Kafka.
T=2s: Serviço B (Estoque) processa o evento e atualiza.
T=2s: Sistemas consistentes!
Entre T=0s e T=2s, o sistema está inconsistente — e isso é normal e esperado.
Idempotência
Idempotência = você pode aplicar a operação 1, 2, 50 vezes que o resultado é o mesmo de aplicar 1 vez.
Exemplo idempotente: "definir o status do pedido 123 para PAGO". Não importa quantas vezes você executa, vai ficar PAGO.
Exemplo NÃO idempotente: "adicionar R$100 ao saldo". Executar 3 vezes credita R$300 — desastre.
Por que isso importa em Kafka? Porque mensagens podem chegar mais de uma vez. Se seus consumers não forem idempotentes, você vai cobrar o cliente 3 vezes, mandar 5 e-mails, etc.
Como tornar consumer idempotente?
Estratégia 1: Identificador único + tabela de processados
CREATE TABLE eventos_processados (
evento_id UUID PRIMARY KEY,
processado_em TIMESTAMP
);Antes de processar: verifica se o evento_id já existe. Se sim, ignora.
Estratégia 2: Operações naturalmente idempotentes
❌ "adicionar 100 ao saldo" → use upserts/sets
✅ "definir saldo = 500"
Estratégia 3: Versionamento (optimistic locking)
Só atualize se a versão atual = X. Se outro processo já atualizou, falha.
Retry — Tentar de Novo Sem Quebrar Tudo
Quando o consumer falha ao processar (ex: API externa indisponível), você precisa tentar de novo. Mas atenção:
Tipos de Erro
- Erros transitórios (rede, timeout, 503): retentativas fazem sentido.
- Erros permanentes (payload inválido, bug no código): retentar não vai mudar nada — vai só consumir CPU à toa.
Estratégias de Retry
Retry imediato — não faça isso:
falhou → tenta de novo na hora → falhou → tenta de novo → ...
Se a API está fora, você martela ela mais ainda.
Retry com Backoff Exponencial:
1ª tentativa: imediata
2ª tentativa: depois de 1s
3ª tentativa: depois de 2s
4ª tentativa: depois de 4s
5ª tentativa: depois de 8s
...com um teto (ex: máximo 60s)
Retry com Jitter: backoff exponencial + um pouco de aleatoriedade. Evita que mil consumers tentem ao mesmo tempo (efeito "thundering herd").
delay = min(maxDelay, base * 2^tentativa) + random(0, 1s)
Onde retentar?
- Em memória (loop dentro do consumer): bom pra retries rápidos (1-3 tentativas).
- Em topics de retry (retry topics): bom pra retries longos. Cada falha é jogada em outro topic com um delay.
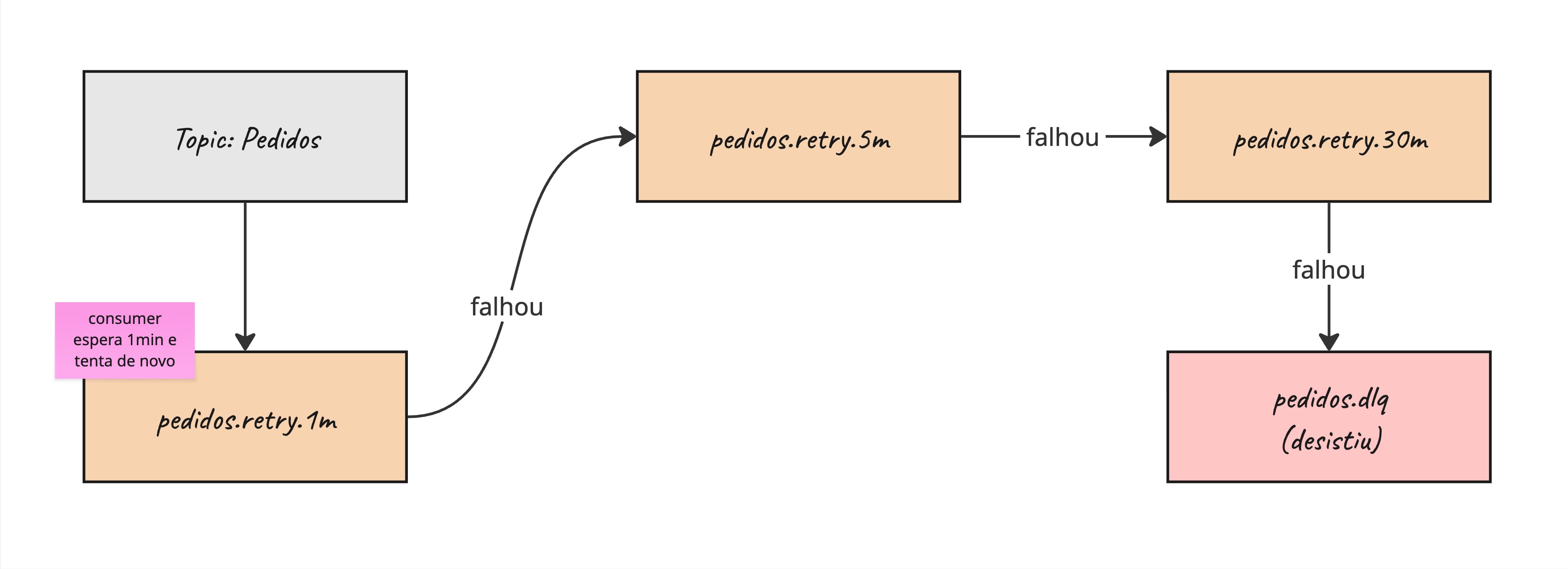
Dead Letter Queue (DLQ)
DLQ é o cemitério das mensagens que não conseguiram ser processadas.
Depois de N tentativas, em vez de ficar tentando pra sempre (e bloqueando a fila), você joga a mensagem numa DLQ — um topic separado. Lá, um humano (ou um job) analisa o que aconteceu.
O que vai pra DLQ?
- Payloads malformados (parsing falhou).
- Bugs descobertos só em produção.
- Dados que dependem de algo inexistente (ex: pedido referencia produto deletado).